AAAI是美国人工智能协会,该协会主办的年会(AAAI, The National Conference on Artificial Intelligence)是一个主要的人工智能学术会议。第34届 AAAI将于2020年2月07日-12日在美国纽约举行。AAAI 2020 共收到的有效论文投稿超过 8800 篇,其中 7737 篇论文进入评审环节,最终收录数量为 1591 篇,收录率为 20.6%。
AAAI 2020现场直播视频回放
-
AAAI-20 Opening Ceremony
-
AAAI Presidential Address
-
AAAI-20 Turing Award Winner Event
-
IAAI-20 Invited Talk:David Cox
-
AAAI-20 Invited Talk: Combining Machine Learning and Control for Reactive Robots- Aude Billard
-
Robert S. Engelmore Memorial Award Lecture: The Third AI Summer - Henry Kautz
-
AAAI-20 Oxford-Style Debate: Academic AI Research in an Age of Industry Labs
-
IAAI/AAAI Joint Invited Talk: AI and Security: Lessons, Challenges and Future Directions - Dawn Song
-
AAAI-20 Invited Talk: The Economic Value of Data for Targeted Pricing
-
AAAI-20 AI History Panel: Advancing AI by Playing Games
-
AAAI-20 Fireside Chat with Daniel Kahneman
-
AAAI-20 Invited Talk: How Not to Destroy the World with AI - Stuart Russell
线下论文分享会视频回放



系列视频论文解读
(持续更新)


李炎洋
李炎洋,东北大学计算机系自然语言处理实验室研究助理,研究方向为机器翻译,已在ACL, COLING, AAAI等人工智能和自然语言处理顶级会议发表多篇论文。
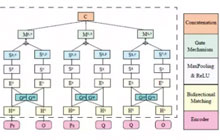
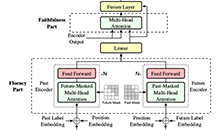
目前神经机器翻译模型主要基于编码器-解码器框架,他们分别对源语言和目标语言进行建模,然后使用注意力机制把双语的表示进行桥接。
本文提出一种联合表示,它同时对源语言和目标语言进行建模,以便更好的捕捉双语直接的关系。在不同数据集上的实验表明我们的方法能够取得比Transformer基线更优秀的结果。


宋广录
宋广录,北京航空航天大学计算机学院2017级研究生,商汤科技见习研究员,研究方向为Computer Vision。
深度学习在人脸检测任务上取得了非常优异的结果,通过设计具备特定感受野的检测器搭配不同尺度特征的有效利用可以比较容易的获得很好的性能。当前算法多为anchor-based的算法,需要一定的设计经验,同时,对于图像输入尺度和模型参数规模也有着一定的要求,这就不可避免的会带来一定的计算量负担。
本文章针对通用人脸检测问题重新探究了检测器感受野和图像输入尺度之间的关系,提出了全新的KPNet人脸检测框架,结合anchor-free的算法设计和bottom-up的检测策略能够让人脸检测器基于低尺度图像输入和轻量级网络结构达到优异的性能,同时具备极快的模型推理速度。


陈汉亭
陈汉亭,北京大学智能科学系硕士三年级在读,同济大学学士,师从北京大学许超教授。研究兴趣主要包括计算机视觉、机器学习和深度学习。在ICCV,AAAI,CVPR等会议发表论文数篇,目前主要研究方向为神经网络模型小型化。
尽管生成性对抗网络(GANs)已经广泛应用于各种图像转换的任务中,但由于其计算量大、存储成本高,很难在移动设备上应用。传统的网络压缩方法侧重于视觉识别任务,而很少考虑生成任务的压缩。
我们提出了一种基于知识蒸馏的生成对抗网络的压缩方法,并分别针对学生网络的生成器和判别器分别设计了蒸馏的损失函数。通过学习教师生成器和判别器中蕴含的信息,学生网络可以使用较少的参数取得和教师网络相似的图像转换性能。


唐业辉
唐业辉,北京大学信息科学技术学院博士二年级研究生,已有多篇文章被CVPR、AAAI等会议接收,研究内容包括深度神经网络正则化方法、模型压缩和网络结构搜索等。
在各种计算机视觉任务中,深度神经网络(尤其是卷积神经网络(CNN))的优越性已得到充分证明。由于深层网络经常被过度参数化以在训练集上获得更高的性能,避免过度拟合非常重要,因此我们提出了特征图扰动方法(disout)来增强深度神经网络的泛化能力,扰动。根据网络中间层的Rademacher 复杂度,确定给定深度神经网络的泛化误差上界。将扰动引入特征图来降低网络的Rademacher复杂度,从而提高其泛化能力。
提出的特征图扰动方法可以方便地应用于全连接层或者卷积层,在基准数据集CIFAR和大尺度数据集ImageNet的实验结果表明,提出的特征图扰动方法可以大幅提高网络的准确率并优于SOTA。


高伽林
高伽林,云从科技算法工程师,上海交通大学博士,研究方向为行为识别、视频动作分析和行人重识别。
随着深度学习技术的发展,以及计算能力的进步(GPU等),现在基于视频的研究领域越来越受到重视。视频与图片最大的不同在于视频还包含了时序上的信息,此外需要的计算量通常也大很多。
目前主要在做视频分析,视频中动作定位相关的工作,视频人类行为分析和视频动作定位在智能监控,在线检测和短视频社交领域都会有相应的应用。
此次主要分享行为动作定位的整个算法流程介绍和相关工作,以及我去年ActivityNet Challenge 2019的技术方案。
另外,此论文已被AAAI 2020收录。


朱聪聪
朱聪聪,宁夏大学2017级硕士研究生,目前于上海大学攻读博士学位。主要研究方向包括:人脸对齐,人脸识别,人脸三维信息检测与重建等。目前以第一作者在AAAI,ICME,ICIP等国际会议发表多篇论文。
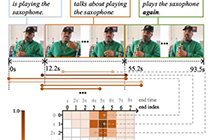
研究面向海量无标注视频人脸关键点定位与跟踪的自监督时空关系推理方法。该方法力图充分挖掘连续视频中邻近人脸关键点间的几何相关性,以此推断出关键点间具有较强判别力的时空关系线索以提高人脸关键点定位与跟踪的稳定性。
具体通过设计一种高效推断的模块机制:在空间域上,算法从静态视频帧中解析人脸的几何特征以对视频人脸的全局结构化约束建模,进而保持不同人脸个体化的差异性;在时间域上,对时序上回环一致性约束,通过评价所追踪定位的关键点能够从未来帧回传到原始帧位置形成自反馈的闭环,从而实现对原始人脸序列潜在的时空关系建模 。


王冰
王冰,牛津大学计算机系2018级博士,研究方向为Robotics & Computer Vision
深度学习在视觉定位方面取得了令人印象深刻的结果。然而基于图像的定位方法普遍缺乏鲁棒性,从而导致较大误差。当前算法多通过图像序列或添加几何约束方法,迫使网络在学习时拒绝动态目标和光照变化对定位的干扰,以获得更好的性能。
本文提出了一种利用注意力机制使网络自动关注并提取具有几何意义的对象和特征,即使仅基于单张图像,也可以实现优于利用图像序列或几何约束方法的定位结果。
通过室内和室外公开数据集上的定位结果和显著图,我们阐述了如何利用注意力机制提取环境中具有几何意义的特征,从而实现最优的相机姿态回归性能。算法细节和源代码可访问:https://github.com/BingCS/AtLoc


洪辉婷
滴滴AI Labs算法工程师,北京理工大学硕士
异质信息网络是当前图嵌入式表示学习领域的一大难题,在本次分享中,讲者将分享如何在不使用专家知识的情况下对异质信息网络进行嵌入式表示学习。


刘宁
2018年12月加入滴滴,在AI Labs智能控制组负责深度模型算法移植及优化工作。博士就读于美国东北大学计算机工程系,
研究领域为深度增强学习、深度模型压缩。博士和工作期间在国际顶级会议AAAI、MICRO、ASPLOS、ISCA、DATE、ICDCS等发表学术论文。
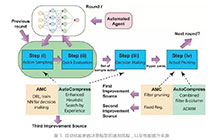
近年来,深度模型在计算机视觉任务上不断刷新性能,已成为研究与应用热点。然而由于参数量庞大、存储和计算代价高,难以部署在资源受限的嵌入式端上。 深度模型压缩技术是解决该问题的一个重要技术。本次分享将介绍外面提出的结合AutoML思想对深度模型进行自动结构化剪枝的AutoCompress算法框架。


王培松
王培松,博士,于2013年在山东大学获软件工程学士学位,2018年在中国科学院自动化研究所获计算机应用博士学位。2018年进入中国科学院自动化研究所模式识别国家重点实验室,担任助理研究员岗位。目前主要从事深度学习、计算机视觉、神经网络高效计算等方面的研究。
二值网络(BNN)由于其对于硬件非常友好,获得了学术界和工业界的广泛关注。虽然二值网络执行效率非常高,但是相对于全精度浮点网络,其精度损失严重。目前二值网络普遍使用sign函数对网络的权值和激活量化到-1和+1,对二值网络的研究方向主要包括提高二值网络的训练技巧、修改网络结构使得网络结构对于二值量化不敏感等,然而二值表达形式却被研究者忽略。在本文中,我们提出了稀疏量化,即对网络激活量化到0和+1,而网络权值依然量化到-1和+1。我们验证了在使用0-1量化时,不会引入任何额外的计算量,但网络性能却获得大幅度提升。同时,针对稀疏二值量化网络中超参选择问题,我们提出一种高效的自动化学习方法,进一步提升二值网络性能。通过实验发现,我们在没有使用任何额外技巧的情况下,网络精度能够达到目前最高水平。


钟皓曦
清华大学普通硕士生,主要研究法律智能。个人主页:http://haoxizhong.github.io/。
文章构建了一个基于司法考试的问答数据集,包含了大约26000道司法考试的选择题。与传统QA数据集不一样的是,法律领域的问答依赖于大量专业知识的理解,和对大量参考资料的结合。本文分析了司法考试的难点,并通过一系列实验证明了现有的模型即使是距离非专业人士的答题水平仍然有很大的差异,而非专业人士与专业人士之间的水平也相去甚远,这也为该数据集的解决带来了巨大的挑战。数据集地址:http://jecqa.thunlp.org/


邵晨泽
邵晨泽,中国科学院计算技术研究所2018级直博生,研究方向为自然语言处理、机器翻译等,博士期间在自然语言处理顶级会议上发表多篇论文,两篇关于非自回归模型的工作分别发表于ACL2019、AAAI2020。
非自回归神经机器翻译模型(NAT)对目标词的生成进行独立的建模,从而显著地提升了翻译速度。然而,对非自回归模型来说,词级别的交叉熵损失函数不合理地要求模型输出与参考译文严格对齐,并且无法准确地建模目标端的序列依赖关系,从而导致其与模型翻译质量的相关性较弱。在本文中,我们提出了基于模型与参考译文间n元组袋差异的训练目标,以该训练目标来训练非自回归模型。我们克服了指数级搜索空间和n元组袋维度巨大的困难,给出了计算n元组袋差异的高效算法,使这个基于n元组袋的训练目标具有可导、高效、易于实现的优点。我们在三个机器翻译数据集上进行了实验验证,结果表明,我们的方法在WMT14英语-德语数据集上取得了约5.0个BLEU值的大幅提升,在另外两个数据集上也有显著提升。


谢婉莹
谢婉莹,北京语言大学硕士一年级研究生。研究方向为机器翻译,自然语言处理。在北京语言大学取得学士学位,目前在中科院计算所实习。
神经机器翻译模型通常采用Teacher Forcing策略来进行训练,在该策略下,每个源句子都给定一个Ground Truth,在每个时间步翻译模型都被强制生成一个0-1分布,0-1分布将所有的概率分布仅通过Ground Truth词语进行梯度回传,词表中其他的词语均被忽略,从而影响了参数训练。为了解决这个问题,我们提出在神经机器翻译模型中引入一个评估模块,对生成的译文从流利度和忠实度两个方面进行评估,并用得到的评估分数用来指导训练阶段译文的概率分布,而在测试的时候,可以完全抛弃该评估模块,采用传统的Transformer模型进行解码。实验中我们与Transformer模型、强化学习模型以及词袋模型进行了比较,我们的方法在中-英、英-罗马尼亚语言对上相比于所有的基线系统翻译效果均取得了显著提升。


钱忱
钱忱,清华大学2016级直博生(导师闻立杰副教授),新加坡国立大学交换生(导师蔡达成教授和冯福利博士后)。主要研究方向为自然语言处理中的文本分类和文本表示。博士期间在人工智能、信息管理、软件工程等相关的国际学术会议AAAI、CIKM、CAISE上以第一作者身份发表论文数篇。
序列文本分类旨在对一条序列文本片段进行标签化。除各个片段内的文本内容以外,考虑文本片段间的上下文依赖依然是影响分类性能的关键因素。先前的文本序列标注技术自左向右地预测对应的文本标签。然而,在决策过程中,不同的文本片段所需上下文依赖不同并且该些依赖并不一定严格按照自左向右地顺序排放。因此,本文提出一种新的跳跃标注模式,先先打标那些需要更少上下文信息的文本片段再考虑那些需要更多上下文的部分。技术上,我们设计了一个辅助的棋盘游戏作为序列文本分类的问题映射。通过将序列文本特征注入到所定义的游戏规则和状态评估策略之中,能有效地推动游戏玩家在每一步中最优化各自的招法,该博弈过程对应到跳跃地产生一段序列标签,此外该棋盘游戏的终局状态对应到最优的预测序列。在多个数据集上的实验结果体现出提出方法的有效性。


高天宇
高天宇,清华大学本科四年级学生,清华大学自然语言处理实验室成员,导师刘知远。其主要研究方向为自然语言处理当中的关系抽取问题,在人工智能和自然语言处理领域的国际会议AAAI、EMNLP上发表过多篇文章。同时他也是开源工具包OpenNRE的主要作者。
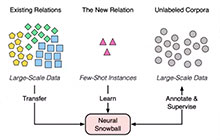
Knowledge graphs typically undergo open-ended growth of new relations. This cannot be well handled by relation extraction that focuses on pre-defined relations with sufficient training data. To address new relations with few-shot instances, we propose a novel bootstrapping approach, Neural Snowball, to learn new relations by transferring semantic knowledge about existing relations. More specifically, we use Relational Siamese Networks (RSN) to learn the metric of relational similarities between instances based on existing relations and their labeled data. Afterwards, given a new relation and its few-shot instances, we use RSN to accumulate reliable instances from unlabeled corpora; these instances are used to train a relation classifier, which can further identify new facts of the new relation. The process is conducted iteratively like a snowball. Experiments show that our model can gather high-quality instances for better few-shot relation learning and achieves significant improvement compared to baselines.


樊俊松
大家好,我是自动化所智能感知中心的在读博士生樊峻菘,导师谭铁牛院士。研究方向主要关于资源受限下的视觉场景解析等。
以图像类别标签为监督信息的弱监督语义分割往往面临目标区域估计不完整的问题。为了缓解这个问题,本文提出了一种对跨图像间关系进行建模的方法。该方法在同类别不同图像之间建立像素级的关系矩阵,并据此从不同的图像间取得互相补充的信息,用以增广原特征并获取更加完整和鲁棒的目标区域估计。实验证明该方法可以有效学得相关目标间的关联关系,辅助得到对整个目标更加完整鲁棒的预测结果,并且在多种质量的初始估计下都能取得显著的提升,具有很好的泛化性。在仅使用图像类别标签作为监督信息下,该方法在 VOC2012 数据集上取得了当时最好的 65.3% mIoU 的测试结果,证明了方法的有效性。


岂凡超
清华大学计算机系自然语言处理与社会人文计算实验室博士生,师从孙茂松教授。研究方向为自然语言处理,已在AAAI、ACL、EMNLP等人工智能和自然语言处理顶级会议发表数篇论文。
反向词典以关于目标词语义的描述为输入,输出目标词以及其他相关词。比如输入“a road where cars go very quickly without stopping”,期望反向词典输出“expressway”、“freeway”、“motorway”等词。反向词典最主要的使用价值在于解决“舌尖现象”(话到嘴边想不起来)。
现有的反向词典模型很难解决高度变化的查询输入以及低频目标词这两个问题。受到人的由描述到词的推断过程的启发,我们提出了多通道反向词典模型,可以同时解决以上两个问题。
我们的模型包括一个句子编码器和多个预测器,预测器可以通过给定的查询文本预测目标词的各种特征,进而帮助确定目标词。我们在中文和英文数据集上评测了我们的模型,实验结果表明我们的模型实现了当前最佳性能(state-of-the-art),甚至在人工真实查询数据集上超过了最流行的商用反向词典系统OneLook。此外我们也进行了定量实验和案例分析来证明我们模型的有效性和鲁棒性。
论文已经在arXiv公开:https://arxiv.org/pdf/1912.08441


秦鹏达
北京邮电大学的一名在读博士生,主要研究领域为自然语言处理领域的信息抽取任务。在博士阶段,本人赴加州大学圣芭芭拉分校William wang教授的自然语言处理实验室进行了为期两年的学术访问,在此期间进行了有关问答系统、自动摘要生成和语言流畅度检测方面的研究工作。
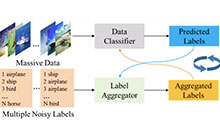
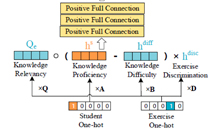
大规模知识图谱在当前的信息系统中具有非常重要的角色。为了扩充知识图谱的规模,之前的工作需要对新增关系标注充足的训练数据集,但这种方式成本昂贵不符合实际要求。本文考虑采用零样本学习方式来解决这个问题。当给定一个新的关系类别,本文尝试直接通过关系类别的文本描述编码类别相关信息。为了完成这个目标,本文采用生成对抗学习思路完成文本信息和知识图谱信息的知识转换。具体来讲,本文希望生成对抗网络的生成器可以有效的通过关系类别文本描述生成关系类别向量表征。在这个前提下,对于新增关系类别的样本预测就转化为监督学习分类任务。

岂凡超
清华大学计算机系自然语言处理与社会人文计算实验室博士生,师从孙茂松教授。研究方向为自然语言处理,已在AAAI、ACL、EMNLP等人工智能和自然语言处理顶级会议发表数篇论文。
反向词典以关于目标词语义的描述为输入,输出目标词以及其他相关词。比如输入“a road where cars go very quickly without stopping”,期望反向词典输出“expressway”、“freeway”、“motorway”等词。反向词典最主要的使用价值在于解决“舌尖现象”(话到嘴边想不起来)。
现有的反向词典模型很难解决高度变化的查询输入以及低频目标词这两个问题。受到人的由描述到词的推断过程的启发,我们提出了多通道反向词典模型,可以同时解决以上两个问题。
我们的模型包括一个句子编码器和多个预测器,预测器可以通过给定的查询文本预测目标词的各种特征,进而帮助确定目标词。我们在中文和英文数据集上评测了我们的模型,实验结果表明我们的模型实现了当前最佳性能(state-of-the-art),甚至在人工真实查询数据集上超过了最流行的商用反向词典系统OneLook。此外我们也进行了定量实验和案例分析来证明我们模型的有效性和鲁棒性。
论文已经在arXiv公开:https://arxiv.org/pdf/1912.08441


彭伟
奥卢大学(芬兰)博士二年级研究生。 已经在AAAI, ICCV,TOMM,FG等会议和期刊上发表多篇论文。研究的内容包括动作识别,深度学习网络设计,情感计算等等。来到芬兰前在厦门大学取得硕士学位,在电子科技大学取得学士学位。
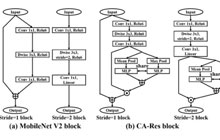
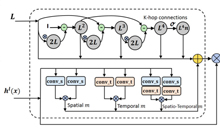
基于skeleton数据的动作识别是计算机视觉领域中一个非常热门的研究话题。使用图卷积(GCN)来建模这种不规则的数据也取得了很好的效果。 但是这个任务中的GCN有两个方面可以去改善。首先, 大部分GCN都提供一个单一的(各层share),固定的矩阵来编码数据节点之间的邻接关系。其次,大部分的GCN都是基于一阶的切比雪夫多项式进行估计的。我们认为,将高层的特征表示限制是低层的拓扑结构当中是一种不合理的做法。此外,一阶的多项式估计并不能很好的捕捉到高阶的邻接关系。本文提出一种基于NAS的GCN设计方案。文章通过多个Graph的功能模块构建出一个搜索空间并且相应的提出一种高效的搜索策略。Searched GCN在两个大规模的Skeleton-based动作识别任务上测试都达到最好的性能。


郑银河
郑银河是清华大学和北京三星研究院的联合培养博士后,合作导师为黄民烈副教授,目前主要从事对话系统领域的研究,包括OOD对话意图检测,低资源设定下的数据增广,个性化对话生成,文本风格迁移等。
本文提出了一个新的基于预训练方法的个性化对话生成模型,与传统的预训练对话模型相比,本文提出了一个注意力路由机制,该机制可以在模型训练过程中更有效地利用个性化稀疏的对话数据,实验表明我们所提出的模型可以生成更为流畅且符合发话者个性化特征的回复,并且我们可以在解码的过程中控制是否在回复中展现发话者的个性化信息。

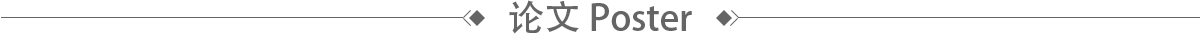
系列论文解读
(持续更新)
-
 北京航空航天大学、DMAI
北京航空航天大学、DMAI 华中科大、阿里巴巴
华中科大、阿里巴巴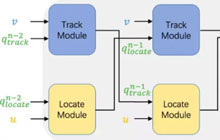 中科院自动化所、腾讯微信AI团队
中科院自动化所、腾讯微信AI团队 -
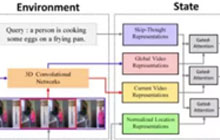
 计算所冯洋组、腾讯微信AI团队
计算所冯洋组、腾讯微信AI团队 -
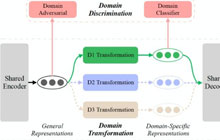
 北航&信工所&微软亚研&阿德莱德大学
北航&信工所&微软亚研&阿德莱德大学





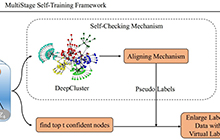
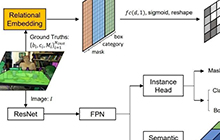

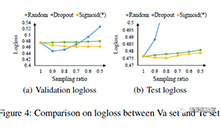
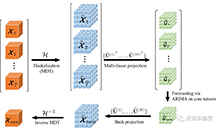









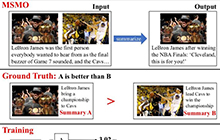
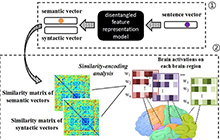

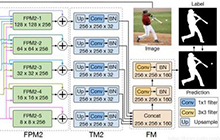

AAAI顶会赞助计划
每年在世界各地举办的 AI 顶会是业内人士的狂欢,来自各个国家的优秀学者和工程师齐聚一堂分享各自的研究成果,探索 AI 行业的边界。对于 AI 学术青年和开发者来讲,这是一个绝佳的学习机会。【AAAI 2020顶会赞助计划】于2019年12月25日正式结束,AI研习社两位用户,分别是来自香港城市大学和华中科技大学的两位同学获得,欢迎大家在关注这两位同学的社区账号。


另外,在顶会赞助计划期间,一共产生了183篇论文推荐,其中不乏有最新的论文推荐;还有20+论文解读文章,其中关于AAAI2020论文解读更是精彩不断~

加入AAAI 顶会小组,第一时间获得最新会议信息
顶会论文解读投稿通道
如何让你的优秀工作,以最短路径,为更多人所了解?
AI 科技评论愿架起这座学者之间的桥梁
促进学术交流,让知识真正流动!
AI科技评论接受高校实验室、企业实验室和个人,在AI科技评论上分享优质的顶会论文解读,可以是最新的顶会会议接收论文,也可以是过去一年顶会会议接收论文。
投稿标准:
1)稿件为个人原创作品
2)如果文章并非首发,请在投稿时提醒并附上已发布链接
投稿方式:
请添加下方微信,备注:顶会投稿+姓名+单位

